X(旧:Twitter)のAIからイラストなどを守る試みの目次を開く ▼
個人サイト制作:サイトマップへ戻る
X(旧:Twitter)のAIからイラストなどを守る試み
イーロン・マスクが開発中のAIは、Grokだけではありません。
Grok
これはX(旧Twitter)で利用できる対話型AIで、xAI社が開発しました。
TruthGPT
これは「真実を追求するAI」として開発されているチャットボットで、xAI社のもう一つのプロジェクトです。
このようなAIから自分のイラストや文章などを守ろうと考えるなら、次のような方法が考えられます。
まずはTwitterの設定でAI学習をoffにする
真っ先に設定方法から手っ取り早く書きます。
AI学習設定をオフにする手順
Xのサイドバーから「設定とプライバシー」をタップ
「プライバシーと安全」を選択
「Grok」をタップ
チェックボックスをオフにする
これでAI学習をオフにすることができます。
とはいえこの設定を行うことで、少なくとも直接的なデータ利用なら防ぐことができます。
AI学習からイラストを守る手順のまとめ
ご興味のある方は、ここだけ読んで頂ければ良いかも?
Twitterの設定でAI学習をoffにする
これだけでもそれなりに違うと思います。
可視的ウォーターマークを入れる
効果が見込めるはず。楽しみながら作れますしね。
不可視的ウォーターマークを入れる
転載防止に効果を発揮するでしょうけど、複数のイラストに入力しようとすると手間ですね。
いろんなプラットフォームがあるので、手順を厳密に区分することは難しいです。
次は個人サイトを作れる、特にhtmlを始めとするソースコードを触れる方向けです。
個人サイトを制作する
クローラーの仕様はともかくとして、安寧を得られるという意味でもお勧めです。
robots.txtを設置する
これでクローラーは形式的にでも排除できます。
ステガノグラフィを使ってイラストに情報を埋め込む
上記の不可視的ウォーターマークの続きです。
イラストをスライスして掲載する
いよいよ大変かと…。
イラストのメタデータに著作権情報を追加
複数画像かつ日本語入力しようとするとかなり面倒です。
私は繰り返される作業をプログラミングでやっつけるタイプです。
小説コンテンツでAI学習を阻止する工夫
いきなり結論から書いちゃうけど、小説ならPDFか画像にしてしまえば、生のテキストデータより収集がやりにくい状態にできると思われます。
例えば、次のように画像化してノイズを載せた文書なんてのはいかがでしょうか?
画像化する
PDFやテキストを画像形式に変換することで、OCRがテキストを認識しにくくなります。
PDFを画像に変換
PDFを開き、各ページをJPEGやPNGなどの画像形式で保存します。
解像度の調整
画像の解像度を適度に下げることで、OCRの精度をさらに低下させることができます。
テキストデータの画像化については、また後日プログラムや各種ツール類をご紹介します。
テキストを歪ませる
テキストを少し歪ませたり、ノイズを加えたりすることで、OCRの精度を下げることができます。
画像編集ソフトを使用
PhotoshopやGIMPなどの画像編集ソフトを使って、テキストをわずかに回転させたり、波状に変形させたりします。
ノイズの追加
テキストの背景にランダムなノイズを加えることで、OCRがテキストを認識しにくくなります。
透かしを入れる
透かしを入れることで、OCRが正確にテキストを認識するのを妨げることができます。
透かしの作成
画像編集ソフトで透かしを作成します。透かしはテキストやロゴなど、透明度を調整したものが一般的です。
透かしの配置
透かしをテキストの上に重ねて配置します。透かしがテキストと重なることで、OCRがテキストを正確に読み取るのを妨げます。
これなんかまさに「小説に載せるウォーターマーク」ですよね。
当サイトではPDFにしています
PDFでも良いと思いますよ?ホーム(アナザーエデン グラスタの入手場所一覧) であったり、アナザーエデン:feinが書いたレポート集 であったり。
OCRとはどういうものか
OCRは画像やスキャンされた文書からテキストを読み取り、デジタルデータに変換する技術です。
紙の文書や画像に含まれるテキストをコンピュータで編集、検索、保存することが可能になります。
OCRは次のように動作しているのです。
スキャン
紙の文書や画像をスキャンしてデジタル画像に変換します。
画像解析
スキャンされた画像のレイアウトを解析し、テキスト部分を特定します。
文字認識
各文字をパターン認識技術を用いて識別し、対応するデジタル文字コードに変換します。
ただ、OCRには利点もあるんです。
手動でのデータ入力を自動化し、時間と労力を節約できます。
OCRを完璧に防ぐのは難しいけど…
完全にOCRを除去することは難しいです。
しかしながら、先ほど説明したように画像化、テキストの歪み、透かしの追加などの方法を組み合わせることで、OCRの精度を下げることができます。
ランダムなノイズをテキストに加えるプログラム
ランダムなノイズをテキストの背景に加えることで、OCR(光学文字認識)がテキストを認識しにくくすることができます。
Pythonをインストールした後、コマンドプロンプトでPillowライブラリのインストールを行います。─ この部分は後述のイラスト関連セクションでもご紹介しています。─
Pillowライブラリをインストールするコマンド
次に、指定した画像にノイズを加え、ノイズを加えた画像を任意の場所に保存するプログラムを用意します。
ノイズを加えるプログラムtextnoise.py
import random
from PIL import Image, ImageDraw
def add_noise(image, noise_level=100):
width, height = image.size
draw = ImageDraw.Draw(image)
for _ in range(noise_level):
x = random.randint(0, width - 1)
y = random.randint(0, height - 1)
r = random.randint(0, 255)
g = random.randint(0, 255)
b = random.randint(0, 255)
draw.point((x, y), fill=(r, g, b))
return image
def process_image(input_image_path, output_image_path, noise_level=1000):
image = Image.open(input_image_path)
noise_image = add_noise(image, noise_level)
noise_image.save(output_image_path)
print(f"Saved noisy image at {output_image_path}")
# 入力画像のパスと出力画像のパスを指定
input_image_path = r'C:\Users\アレコレ\OneDrive\_fein\google cloud\fein-sites-dev1\www\another-eden\anaimage\ハイエンドコンテンツ対策.png'
output_image_path = r'C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\output_image.png'
# 画像を処理
process_image(input_image_path, output_image_path)
このプログラムの説明をしますね。
add_noise関数
指定した画像にランダムなノイズを加えます。
process_image関数
入力画像を読み込み、add_noise関数を使用してノイズを加え、指定された場所に保存します。
ファイルパスの設定
input_image_pathにノイズを加えたい画像のパスを指定します。
output_image_pathにノイズを加えた画像を保存したい場所のパスを指定します。
その気になれば、こういうプログラミングでOCRがテキストを認識しにくい画像を作成することだってできます。
AI学習妨害ツールについて
こちらのページと併せてX(旧:Twitter)の変化にどう対処するか もご覧いただけると、現在の「SNS移住」に関する対応について、ある程度は掴めるかと思います。
AI学習妨害ツールのリスト
個人サイトの「やることリスト」 にも同じことは書いてありますが、こちらもことあるごとに更新していきますね。
Nightshade
Glaze
emamori
Mist
画像にウォーターマークを追加
画像にウォーターマークを追加する方法はいくつかあります。
スマホアプリを使う方法
PhotoDirector モバイル
Photoshop Express
PicsArt
PCソフトを使う方法
PhotoDirector
Promeo
GIMP
GIMP なら、私も以前使っていましたね。
フリーソフトをダウンロードしてインストールします。
画像をインポートし、レイヤー機能を使ってテキストや画像を追加します。
不透明度や位置を調整して保存します。
オンラインツールを使う方法
Canva のウェブサイトにアクセスし、アカウントを作成します。
画像をアップロードし、テキストや画像を追加してウォーターマークを作成します。
不透明度や位置を調整して保存します。
これらの方法を使って、簡単に画像にウォーターマークを追加することができます。
ウォーターマークはAI学習を防げるのか
ウォーターマークというのは、画像や動画にロゴやテキストを重ねて表示することで著作権を主張したり、無断使用を防ぐための手段です。
可視的ウォーターマーク
画像や動画の上にロゴやテキストを重ねることで、視覚的に著作権を主張します。
不可視的ウォーターマーク
デジタルデータに埋め込まれるもので、肉眼では見えません。
不可視的ウォーターマークの入れ方
不可視的ウォーターマークは画像や動画に肉眼では見えない形で情報を埋め込む技術です。
不可視的ウォーターマークを入れるツール
ソフトウェアならAdobe PhotoshopやGIMP。Watermarkly やPhotoMarks 。
AI学習を防ぐ観点からのウォーターマーク
あるいは、ウォーターマークを画像全体に濃く入れると良いのかもしれません。
このように著作権保護や無断使用防止に有効な手段ではありますが…AI学習を完全に防ぐことは難しいかと。
ウォーターマークと著作権
ウォーターマークを無断で除去してはいけませんよ?
著作権侵害
ウォーターマークを除去して他人の作品を無断で使用することは、著作権法に違反する行為です。
契約違反
画像や動画の使用に関する契約でウォーターマークの保持が義務付けられている場合、その除去は契約違反となります。
不正競争防止法
商業的な目的でウォーターマークを除去し、他人の作品を自分のものとして偽る行為は、不正競争防止法に抵触する可能性があります。
だからさー…ダメなものはダメだ と考えて頂ければ良いでしょう。
では、ここから発展編へ移ります。
発展編:個人サイトでAI学習を防ぐ!
SNSやイラストコミュニケーションサービスを使っている、言い換えるとインターネットにコンテンツをアップロードしている以上、何らかのリスクはあるでしょうね。xfolio はとても優秀なプラットフォームだと思いますが、動作が重いという話を聞きます…
それで…そういう状況だからいっそのこと個人サイトを作ってしまおうというのが現在の潮流なのですが、さすがに個人サイトともなれば、かなりの自由が利きますよ?
プラットフォームを作るとはどういうことか
プラットフォームとは、コンピュータやソフトウェアが動くための土台のようなものです。
X(旧:Twitter)
X(旧:Twitter)は、インターネット上にあるソーシャルメディアプラットフォームです。
pixiv
pixivは、イラストコミュニケーションサービスのプラットフォームです。
個人サイト
個人サイトも同様に、ウェブサーバーというプラットフォーム上で動いています。
要するにプラットフォームは、アプリケーションやサービスが動くための「舞台装置」と考えると分かりやすいかもしれませんね。
個人サイト制作はプラットフォーム制作
X(旧:Twitter)は経営方針が嫌い、Pixivもなんかアレ、xfolioはちょっと敷居が…
でも個人サイトだから最強というのも、ちょっと一考の余地ありですよ?
とは言え個人サイトであれば、ただ単にプラットフォームを間借りするだけの状態よりも、ユーザーの自由が利く場面が非常に多いのです。
自分でコーディング&プログラミングできれば最高です
これは…そりゃあそうでしょうと言うしかありません。
可能ならレンタルサーバーではなくクラウドを使おう
レンタルサーバーも素晴らしいサービスがいっぱいあります。
Google Cloud(このサイトの住処です)
Microsoft Azure
Amazon Web Service
これらのクラウドに個人サイトをアップロードするとき、サーバーの「リージョン」というものを選択できるのです。
現在、AI学習に関する最も厳しい法律を課しているのはEU諸国です。
でもクラウドはIT知識を要求します…
ちゃんと時間作って勉強すれば大したことありません。
では、気を取り直して!
イラスト表示にJavaScriptを経由する
ちょっと言い方が難しいですから、簡単に言い換えます。
例えば私のサイトであれば、ユーザーが画像のところにまでスクロールしてくると、徐々に画像が表示されるようなアニメーションが付いています。アナザーエデン のフィーネです。
これはJavaScriptで制御しているのですが、ブラウザでJavaScriptの動作を抑止すると、草花の写真を除くほぼ全ての画像が閲覧不能になります。
とはいえ人間の目には普通に見えるのですよ。
ただし、AIは進化しています。
Apify
Webサイトをスクレイピングし、データを収集するためのプラットフォーム。
Crawlee
Webサイトを自動的に巡回し、データを収集するためのツール。
クローラーとは特定の目的でWebサイトを自動的に巡回し、コンテンツを収集するプログラムのことを指します。
さて、これらのクローラー(亜種も含めて)はJavaScriptを実行することで、動的に生成されるコンテンツを取得する能力を持っています。
robots.txtファイルの設定
ウェブクローラーに対して特定のページやディレクトリをクロールしないよう指示できます。
まず、いろんなウェブサイトビルダーがありますが、robots.txtファイルを置けるものとそうでないものがあります。
robots.txtを置けるウェブサイトビルダー
私が以前からお勧めしているGoogle SitesやBloggerではrobots.txtファイルの設定が可能です。
WordPress
プラグインを使用してrobots.txtファイルを編集できます。
Wix
SEO設定からrobots.txtファイルをカスタマイズできます。
Squarespace
デフォルトのrobots.txtファイルが提供されますが、カスタム設定も可能です。
Weebly
SEOツールを使ってrobots.txtファイルを編集できます。
Shopify
テーマのコードを編集することでrobots.txtファイルをカスタマイズできます。
これらのプラットフォームを利用することで、検索エンジンのクローラーに対する指示を細かく設定することができます。
robots.txtの書き方
robots.txtはウェブサイトの管理者が検索エンジンのクローラーに対して、特定のページやディレクトリへのアクセスを制御するためのテキストファイルです。
robots.txtの基本構成
robots.txtファイルは、以下のような構成で記述されます。
User-agent: [クローラー名]
Disallow: [禁止するパス]
Allow: [許可するパス]
Sitemap: [サイトマップのURL]
User-agent
クローラーの名前を指定します。全てのクローラーに対して指示を出す場合は * を使います。
Disallow
クローラーにアクセスさせたくないページやフォルダを指定します。/ を使うと、サイト全体がブロックされます。
Allow
Disallowでブロックした中でも、特定のパスを許可したい場合に使います。
Sitemap
サイトマップのURLを指定します。
robots.txtの具体例
全てのクローラーに対して全てのページを許可
全てのクローラーに対して全てのページをブロック
User-agent: *
Disallow: /
特定のフォルダ(例:/private/)のみをブロック
User-agent: *
Disallow: /private/
特定のファイル形式(例:pdfファイル)をブロック
User-agent: *
Disallow: /*.pdf$
robots.txtの設置場所
robots.txtファイルは、ウェブサイトのルートディレクトリに配置します。
robots.txtの確認方法
Google Search Consoleなどのツールを使用して、robots.txtファイルの設定を確認し、誤りがないかをチェックできます。
robots.txtの注意点
robots.txtは法的拘束力がないため、悪意のあるクローラーは無視することがあります。
では、いよいよプログラミングに移ります。
発展編:プログラミングでAI学習と無断転載を防ぐ!
これも個人サイトの利点だと思うんですよね。
ステガノグラフィ技術を使って画像に情報を埋め込む
ステガノグラフィ技術を使って、画像に情報を埋め込む「Stegano」というツールがあります。
Stegano公式サイト
Steganoを使って不可視的ウォーターマークを入れる方法を書いていきます。
WindowsにPythonをインストール
ここからはコマンドプロンプトを使っていきます。
1. Pythonのダウンロード
Pythonの公式サイト にアクセスします。画面上部の「Downloads」メニューから「Windows」を選択します。
最新バージョンのPythonをダウンロードします。
2. Pythonのインストール
ダウンロードしたインストーラーを実行します。
インストール画面で「Add Python 3.x to PATH」にチェックを入れます。
「Install Now」をクリックしてインストールを開始します。
インストールが完了したら、「Close」をクリックしてインストーラーを閉じます。
3. インストールの確認
Windowsの検索バーに「cmd」と入力してコマンドプロンプトを開きます。
コマンドプロンプトに「python --version」と入力してEnterキーを押します。
インストールされたPythonのバージョンが表示されれば、インストールは成功です。
これでPythonのインストールが完了し、使用する準備が整いました。
steganoをインストールできたら…
ステガノグラフィを使うなら画像はpng形式で
JPEG形式の画像に隠されたデータは、JPEGの圧縮アルゴリズムによって破損する可能性があります。
jpgをまとめてpngにするjpgpng.py
import os
from PIL import Image
def convert_jpg_to_png(input_directory, output_directory):
if not os.path.exists(output_directory):
os.makedirs(output_directory)
for filename in os.listdir(input_directory):
if filename.lower().endswith(('.jpg', '.jpeg')):
input_path = os.path.join(input_directory, filename)
output_path = os.path.join(output_directory, os.path.splitext(filename)[0] + '.png')
img = Image.open(input_path)
img.save(output_path, 'PNG')
print(f"Converted {input_path} to {output_path}")
# 入力ディレクトリのパス
input_directory = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_metadata"
# 出力ディレクトリのパス
output_directory = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_metadata\metainput"
convert_jpg_to_png(input_directory, output_directory)
Steganoを使って画像に不可視的ウォーターマークを埋め込むプログラム
まずは完成品の画像を陳列します。
こちらは不可視的ウォーターマークを入れている写真です。
まずは1枚の画像を扱うpythonから行きましょう。
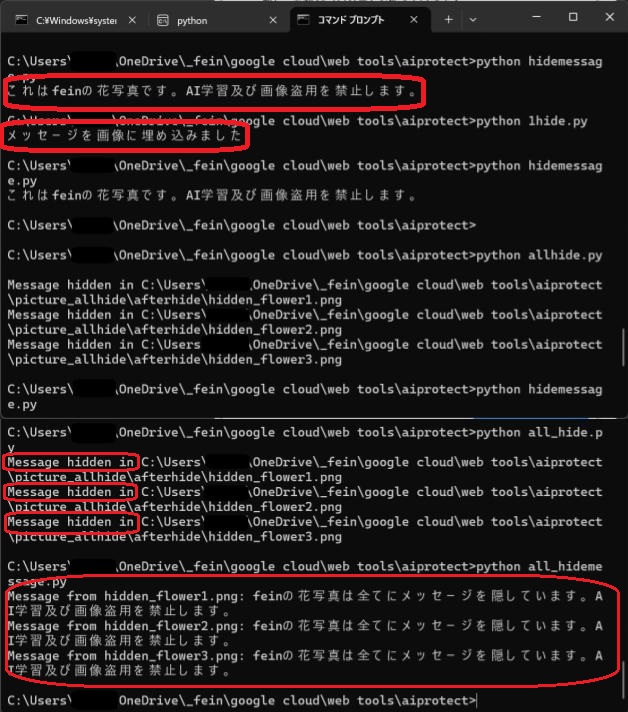
1つの画像にメッセージを隠す1hide.py
from stegano import lsb
import base64
# 隠すメッセージをUTF-8でエンコードし、Base64でエンコードする
message = base64.b64encode("これはfeinの花写真です。AI学習及び画像盗用を禁止します。".encode('utf-8')).decode('utf-8')
# メッセージを隠す
secret = lsb.hide(r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_1hide\flower1.png", message)
secret.save(r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_1hide\output_image.png")
print("メッセージを画像に埋め込みました")
これはシンプルに1枚の画像へメッセージを隠すプログラムです。
隠されたメッセージを確認するhidemessage.py
from stegano import lsb
import base64
image_path = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_1hide\output_image.png" # 任意の画像ファイルのパスを指定
# 隠されたメッセージを読み取る
message = lsb.reveal(image_path)
# メッセージをBase64でデコードし、UTF-8でデコードする
if message is not None:
decoded_message = base64.b64decode(message).decode('utf-8')
print(decoded_message)
else:
print("メッセージが見つかりませんでした")
これは隠されたメッセージを確認するプログラムです。
フォルダ内の画像全てにまとめてメッセージを隠すall_hide.py
import os
from stegano import lsb
import base64
def hide_message_in_directory(input_directory, output_directory, message):
# メッセージをUTF-8でエンコードし、Base64でエンコードする
encoded_message = base64.b64encode(message.encode('utf-8')).decode('utf-8')
if not os.path.exists(output_directory):
os.makedirs(output_directory)
for filename in os.listdir(input_directory):
file_path = os.path.join(input_directory, filename)
if filename.lower().endswith('.png'):
secret = lsb.hide(file_path, encoded_message)
new_file_path = os.path.join(output_directory, f"hidden_{filename}")
secret.save(new_file_path)
print(f"Message hidden in {new_file_path}")
input_directory = r"path_to_your_input_directory" # 画像が保存されている入力ディレクトリのパス
output_directory = r"path_to_your_output_directory" # メッセージを隠した画像を保存する出力ディレクトリのパス
message = "隠したいメッセージ"
hide_message_in_directory(input_directory, output_directory, message)
これはフォルダ内の画像全てにメッセージを隠すプログラムです。
フォルダ内にある全て画像に隠されたメッセージを確認するall_hidemessage.py
from stegano import lsb
import base64
import os
def reveal_message_from_directory(directory):
for filename in os.listdir(directory):
file_path = os.path.join(directory, filename)
if filename.lower().startswith('hidden_') and filename.lower().endswith('.png'):
message = lsb.reveal(file_path)
if message is not None:
decoded_message = base64.b64decode(message).decode('utf-8')
print(f"Message from {filename}: {decoded_message}")
else:
print(f"No message found in {filename}")
output_directory = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_allhide\afterhide" # メッセージを隠した画像を保存する出力ディレクトリのパス
reveal_message_from_directory(output_directory)
これはフォルダ内の画像全てに隠されたメッセージを確認するプログラムです。
こちらも完成品を置きましょう。
こちらは不可視的ウォーターマークを入れていない写真1です。
こちらは不可視的ウォーターマークを入れていない写真2です。
こちらは不可視的ウォーターマークを入れていない写真3です。
こちらは不可視的ウォーターマークを入れている写真1です。
こちらは不可視的ウォーターマークを入れている写真2です。
こちらは不可視的ウォーターマークを入れている写真3です。
ステガノグラフィとは何か
ステガノグラフィ(Steganography)とは、情報を他のデータに埋め込んで、その存在自体を隠す技術のことです。
最も注目すべきなのは、この方法を使うと、画像の見た目にほとんど変化がないことですよ。
ちなみに、ITのお勉強という意味であれば、このステガノグラフィは誰でも知ってるレベルの基本です。
画像をスライスして安易な収集を防ぐ
ここでは、pythonで次のようなことをするプログラムを組みます。
ある1枚の画像を縦もしくは横に分割する
その画像は任意のディレクトリに保存できる
分割された画像を綺麗に表示できるよう、htmlコードをテキスト出力させる
個人サイトに画像を分割して表示することで、簡単に収集できないようにします。
いかがでしょうか?
学生時代のWebサイトでは、ここまでは実装しなかったですね。
画像をスライスしてhtmlも出力するsliceimg.py
import os
from PIL import Image
def split_image(image_path, output_directory, split_direction='horizontal', num_splits=10):
if not os.path.exists(output_directory):
os.makedirs(output_directory)
img = Image.open(image_path)
img_width, img_height = img.size
split_images = []
if split_direction == 'horizontal':
split_height = img_height // num_splits
for i in range(num_splits):
box = (0, i * split_height, img_width, (i + 1) * split_height)
split_img = img.crop(box)
split_img_path = os.path.join(output_directory, f"split_{i + 1}.png")
split_img.save(split_img_path)
split_images.append(split_img_path)
elif split_direction == 'vertical':
split_width = img_width // num_splits
for i in range(num_splits):
box = (i * split_width, 0, (i + 1) * split_width, img_height)
split_img = img.crop(box)
split_img_path = os.path.join(output_directory, f"split_{i + 1}.png")
split_img.save(split_img_path)
split_images.append(split_img_path)
return split_images
def generate_html(image_paths, output_html_path):
html_content = """
<html>
<head>
<title>Image Slices</title>
</head>
<body>
<div style="width: 100%; overflow: hidden;">
<div style="float: left; width: 60%;">
<p>ここにテキストが入ります。このテキストは画像の左側に回り込みます。</p>
</div>
<div style="float: right; width: 40%;">
"""
for image_path in image_paths:
html_content += f'<img src="{image_path}" alt="Image Slice" style="display: block; width: 100%;">\n'
html_content += """
</div>
</div>
</body>
</html>
"""
with open(output_html_path, 'w') as f:
f.write(html_content)
# 入力画像のパス
image_path = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_slice\slice_a.png"
# 出力ディレクトリのパス
output_directory = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_slice\cat_a"
# 出力HTMLファイルのパス
output_html_path = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_slice\cat_a.html"
# 画像を分割
split_images = split_image(image_path, output_directory, split_direction='horizontal', num_splits=10)
# HTMLファイルを生成
generate_html(split_images, output_html_path)
print(f"Images have been split and saved to {output_directory}. HTML file has been generated at {output_html_path}.")
このスクリプトではsplit_image関数が画像を分割し、generate_html関数が分割された画像を表示するHTMLコードを生成します。
split_image関数が画像を分割する部分を担当しています。
例えば、num_splits=2と指定した場合、画像は2つの部分に分割されます。
関数の動作の説明
横方向に分割する場合(split_direction='horizontal')
画像の高さをnum_splitsで割り、各部分の高さを計算します。
画像を上から下に向かってnum_splits個の部分に分割します。
縦方向に分割する場合(split_direction='vertical')
画像の幅をnum_splitsで割り、各部分の幅を計算します。
画像を左から右に向かってnum_splits個の部分に分割します。
例えば、num_splits=4と指定すると、画像は4つの部分に分割されます。
num_splitsを20などの大きな数に設定すると、その分だけ自動的に<img>タグが生成されます。
仮にnum_splits=20と設定した場合、split_image関数は画像を20個に分割し、それぞれの分割画像のパスをimage_pathsリストに追加します。
全体の流れを再確認
split_image関数で画像を20個に分割し、分割された画像のパスをimage_pathsリストに格納します。
generate_html関数でimage_pathsリストを受け取り、各画像のパスに対して<img>タグを生成し、HTMLファイルを作成します。
htmlをpythonに出力させた後の作業
これなんですよ。
元のイラストのコピーを安全なディレクトリに配置
上記の「sliceimg.py」を実行する
スライスされた画像を、個人サイトの画像ディレクトリへ配置
生成されたhtmlを、個人サイトの任意の箇所へコピー貼り付け
貼り付けたhtmlコードを、個人サイトのディレクトリ構造に合うよう変更
動作確認
アップロード
手順の4と5のハードルが高いですよね…
画像のメタデータに著作権情報を追加
画像ファイルのプロパティの詳細タブに表示される情報がメタデータです。
これらのフィールドに著作権情報を入力することで、画像のメタデータに著作権情報を追加することができます。
このセクションでは、メタデータを追加した草花の写真を添えていきましょうね🌸
複数画像のメタデータにまとめて情報を入力する
画像のメタデータに著作権情報を追加するPythonスクリプトの例を紹介します。
すでに上記でPythonのインストールはご紹介しました。
Pillowライブラリをインストールするコマンド
次に、以下のスクリプトを使用して、画像のメタデータをまとめて追加します。
メタデータをまとめて入力するプログラムpngmetadata.py
import os
from PIL import Image, PngImagePlugin
def add_metadata_to_png_images(input_directory, output_directory, metadata_dict):
if not os.path.exists(output_directory):
os.makedirs(output_directory)
for filename in os.listdir(input_directory):
if filename.lower().endswith('.png'):
input_path = os.path.join(input_directory, filename)
output_path = os.path.join(output_directory, filename) # 出力先を指定
img = Image.open(input_path)
metadata = PngImagePlugin.PngInfo()
for key, value in metadata_dict.items():
metadata.add_text(key, value)
img.save(output_path, pnginfo=metadata)
print(f"Metadata added to {output_path}")
# 入力ディレクトリのパス
input_directory = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_metadata\metainput"
# 出力ディレクトリのパス
output_directory = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_metadata\metaafter"
# メタデータ情報
metadata_dict = {
"Copyright": "© 2023 fein. All rights reserved.",
"Author": "fein_den_scoth_mn"
}
add_metadata_to_png_images(input_directory, output_directory, metadata_dict)
順を追って説明します。
ライブラリのインポート
osモジュールとPillow(PIL)ライブラリのImageとPngImagePluginをインポートしています。
関数の定義
add_metadata_to_png_imagesという関数を定義しています。
出力ディレクトリの作成
関数の最初で、指定された出力ディレクトリが存在しない場合、新たにディレクトリを作成します。
ファイルの処理
入力ディレクトリ内のファイルを一つずつ処理します。
画像の読み込みとメタデータの追加
対象ファイルのパスを取得し、その画像を開きます。
画像の保存
メタデータが追加された画像を、指定された出力ディレクトリ内に同じファイル名で保存します。
処理の完了メッセージ
各画像ファイルに対して、メタデータが追加されたことを示すメッセージを表示します。
次に、以下のスクリプトを使用して、画像にメタデータが入っているか確認します。
メタデータをまとめてチェックするpngmetacheck.py
import os
from PIL import Image
def print_png_metadata(input_directory):
for filename in os.listdir(input_directory):
if filename.lower().endswith('.png'):
input_path = os.path.join(input_directory, filename)
img = Image.open(input_path)
metadata = img.info
print(f"Metadata for {input_path}:")
for key, value in metadata.items():
print(f" {key}: {value}")
# 入力ディレクトリのパス
input_directory = r"C:\Users\アレコレ\OneDrive\_fein\google cloud\web tools\aiprotect\picture_metadata\metaafter"
print_png_metadata(input_directory)
ここも説明しないとね。
ライブラリのインポート
osモジュールとPillow(PIL)ライブラリのImageモジュールをインポートしています。
関数の定義
print_png_metadataという関数を定義しています。
ファイルの処理
入力ディレクトリ内のファイルを一つずつ処理します。
画像の読み込みとメタデータの取得
対象ファイルのパスを取得し、その画像を開きます。
メタデータの表示
取得したメタデータをキーと値のペアで表示します。
メタデータの基本をおさらいする
メタデータには画像形式によって扱える内容が異なる場合がありますが、共通して利用できるメタデータも存在します。
共通して扱えるメタデータ
著作権情報 (Copyright)
著作者の権利を表す情報です。
作者情報 (Author)
画像の作成者または著作者の名前です。
タイトル (Title)
画像のタイトルや名前です。
説明 (Description)
画像の内容や説明です。
キーワード (Keywords)
画像に関連するキーワードやタグです。
あまり細かくは書かないけど、JPG形式ではExifメタデータ、PNG形式では独自のチャンクを使用してメタデータを保存します。
このページでは著作権情報と作者情報のみをまとめて追加しています。
著作権情報
(Copyright) は、特定の作品に対する法的な権利を示します。これは通常、作品の作成者または著作権を所有する個人や団体によって主張されるものです。
作者情報
(Author) は、実際に作品を作成した個人の名前です。これは作品のクリエイターやアーティスト、著者の名前を示します。著作権情報とは異なり、作者情報は必ずしも法的権利に関係しないことがありますが、作品のクリエイターを特定するために重要です。
短くまとめると…
日本語にも対応させる場合
ここではアルファベットのみとしましたが、著作権情報や作者情報を日本語で書きたい場合はどうなるでしょう。
with open('file.txt', 'r', encoding='utf-8') as file:
content = file.read()
ただ、各々の環境で試してみないことには正確なことは分かりません。
とりあえず、以上です
しかし、前述したようにこのページも拡張していこうと思います。
サイトマップ
アナザーエデンの強敵戦やストーリーコンテンツのリスト、お勧めバッジなどを掲載したコーナーです。
個人でウェブサイトを作るにはどうすればいいか。
ゲームとパソコンだけじゃなく、アウトドアも趣味なんです。
ページ上部へ戻る

.JPG)
.JPG)
.JPG)
.JPG)

.JPG)

.JPG)
.JPG)
.JPG)
.JPG)
.JPG)
.JPG)
.jpg)





.JPG)